Language-guided robot task planning, vision-language interpreters, and integrated task and motion planning (TAMP) for manipulation.
This theme covers vision-language models for robot task planning: interpreting natural language instructions and scene understanding to generate executable manipulation plans. It includes the Vision-Language Interpreter (ViLaIn) for task planning, grounded vision-language interpreters for integrated task and motion planning (TAMP), and one-shot vision-language guided motion generation (e.g. KeyMPs for occlusion-rich tasks with DMPs). The goal is to bridge high-level language instructions and low-level motion execution for flexible, interpretable robot control.
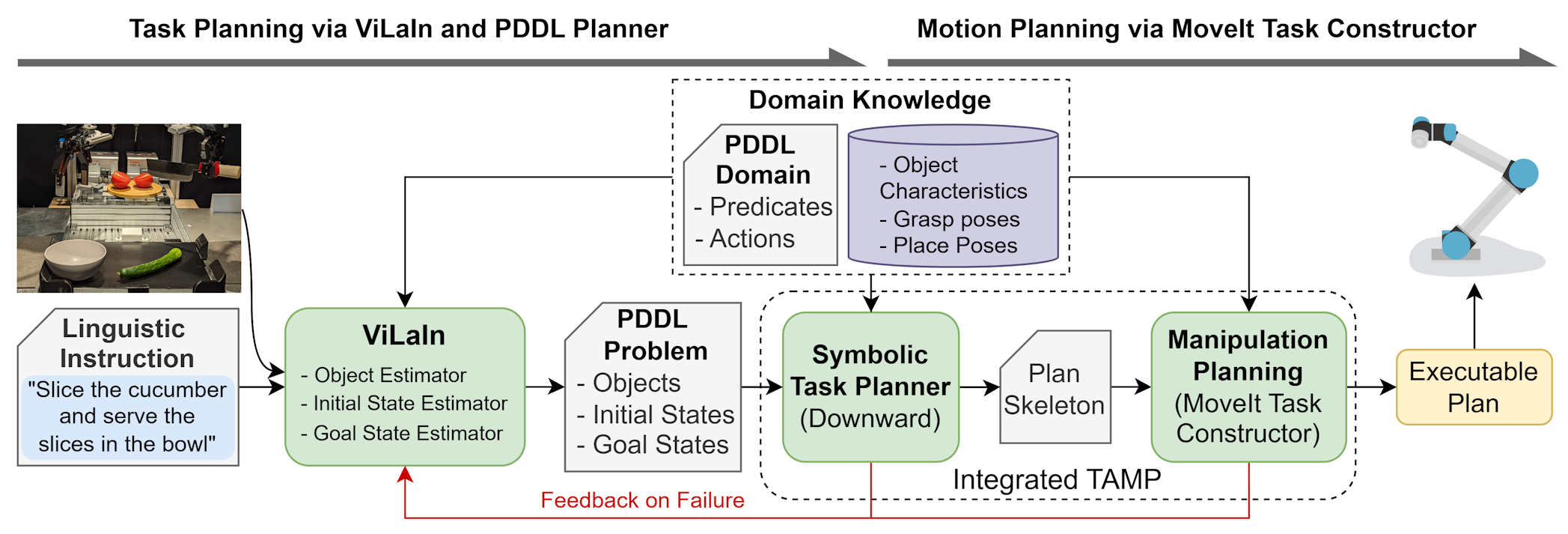
@misc{siburian2025groundedvisionlanguageinterpreterintegrated,title={Grounded Vision-Language Interpreter for Integrated Task and Motion Planning},author={Beltran-Hernandez, Cristian C. and Siburian, Jeremy and Shirai, Keisuke and Hamaya, Masashi and Görner, Michael and Hashimoto, Atsushi},year={2026},archiveprefix={arXiv},primaryclass={cs.RO},}
2025
IEEE Access
KeyMPs: One-Shot Vision-Language Guided Motion Generation by Sequencing DMPs for Occlusion-Rich Tasks
Edgar Anarossi, Yuhwan Kwon, Hirotaka Tahara, Shohei Tanaka, Keisuke Shirai, and 4 more authors
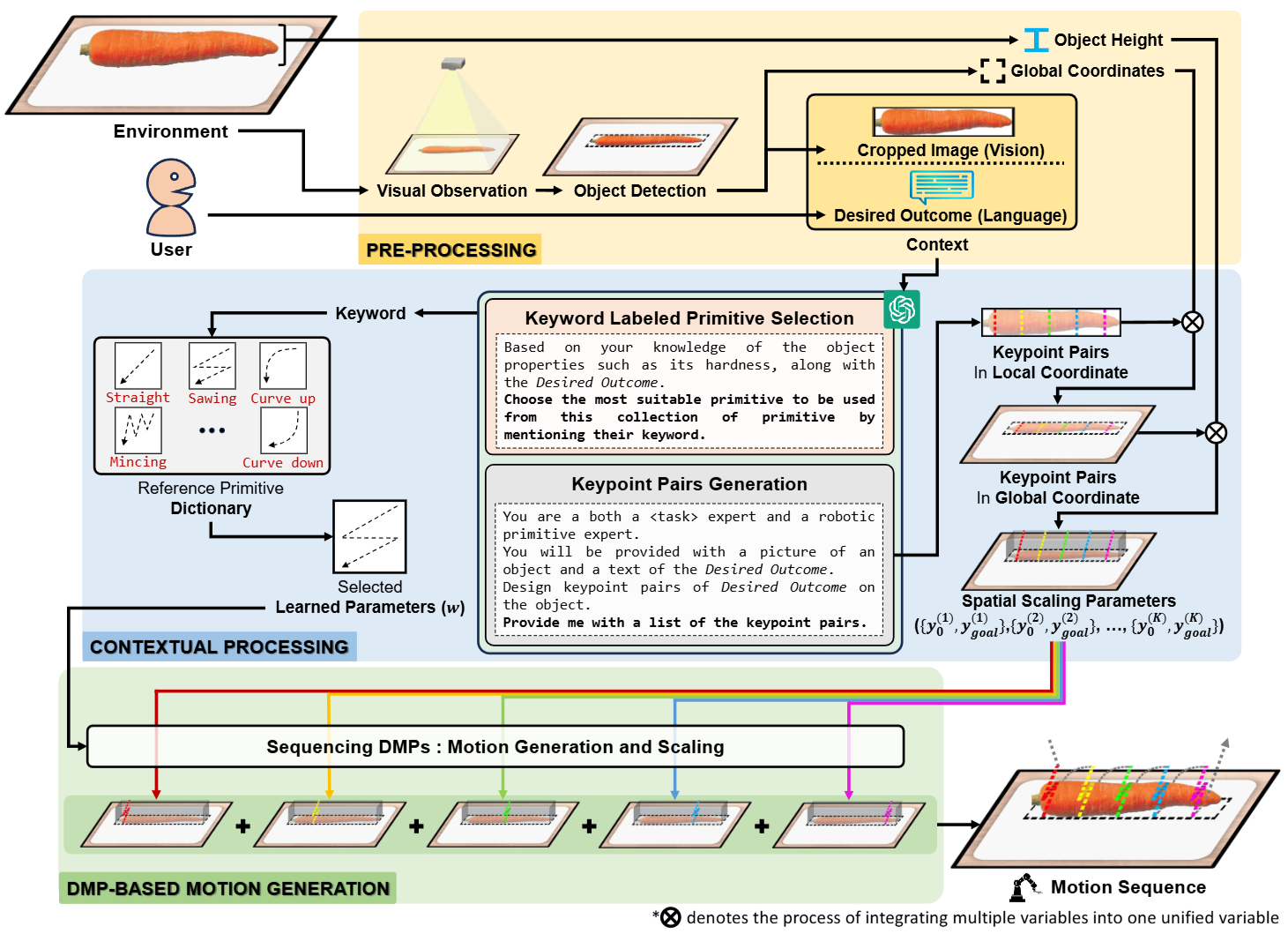
@misc{anarossi2025keympsoneshotvisionlanguageguided,title={KeyMPs: One-Shot Vision-Language Guided Motion Generation by Sequencing DMPs for Occlusion-Rich Tasks},author={Anarossi, Edgar and Kwon, Yuhwan and Tahara, Hirotaka and Tanaka, Shohei and Shirai, Keisuke and Hamaya, Masashi and Beltran-Hernandez, Cristian C. and Hashimoto, Atsushi and Matsubara, Takamitsu},journal={IEEE Access},year={2025},volume={13},number={},pages={125420-125441},doi={10.1109/ACCESS.2025.3588975},}
2024
ICRA
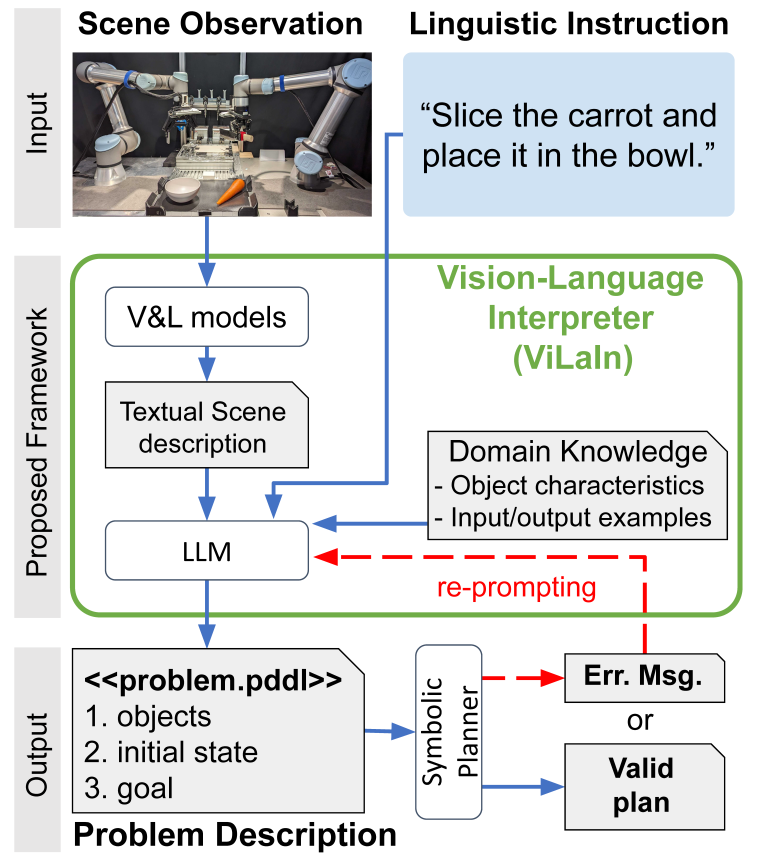
Vision-Language Interpreter for Robot Task Planning
Keisuke Shirai, Cristian C. Beltran-Hernandez, Masashi Hamaya, Atsushi Hashimoto, Shohei Tanaka, and 4 more authors
In IEEE International Conference on Robotics and Automation (ICRA), 2024
@inproceedings{shirai2023vision,author={Shirai, Keisuke and Beltran-Hernandez, Cristian C. and Hamaya, Masashi and Hashimoto, Atsushi and Tanaka, Shohei and Kawaharazuka, Kento and Tanaka, Kazutoshi and Ushiku, Yoshitaka and Mori, Shinsuke},title={Vision-Language Interpreter for Robot Task Planning},year={2024},booktitle={IEEE International Conference on Robotics and Automation (ICRA)},}